Flink基本概念
Flink是什么?
Apache Flink 是一个在有界数据流和无界数据流上进行有状态计算分布式处理引擎和框架。Flink 设计旨在所有常见的集群环境中运行,以任意规模和内存级速度执行计算。
以上是来自官方文档的介绍
我自己的使用场景是,将flink作为一个流式计算引擎,将数据流从kafka中读取,经过一系列的计算,最后将结果写入到kafka或者mysql中,供其他系统使用。
Flink的架构
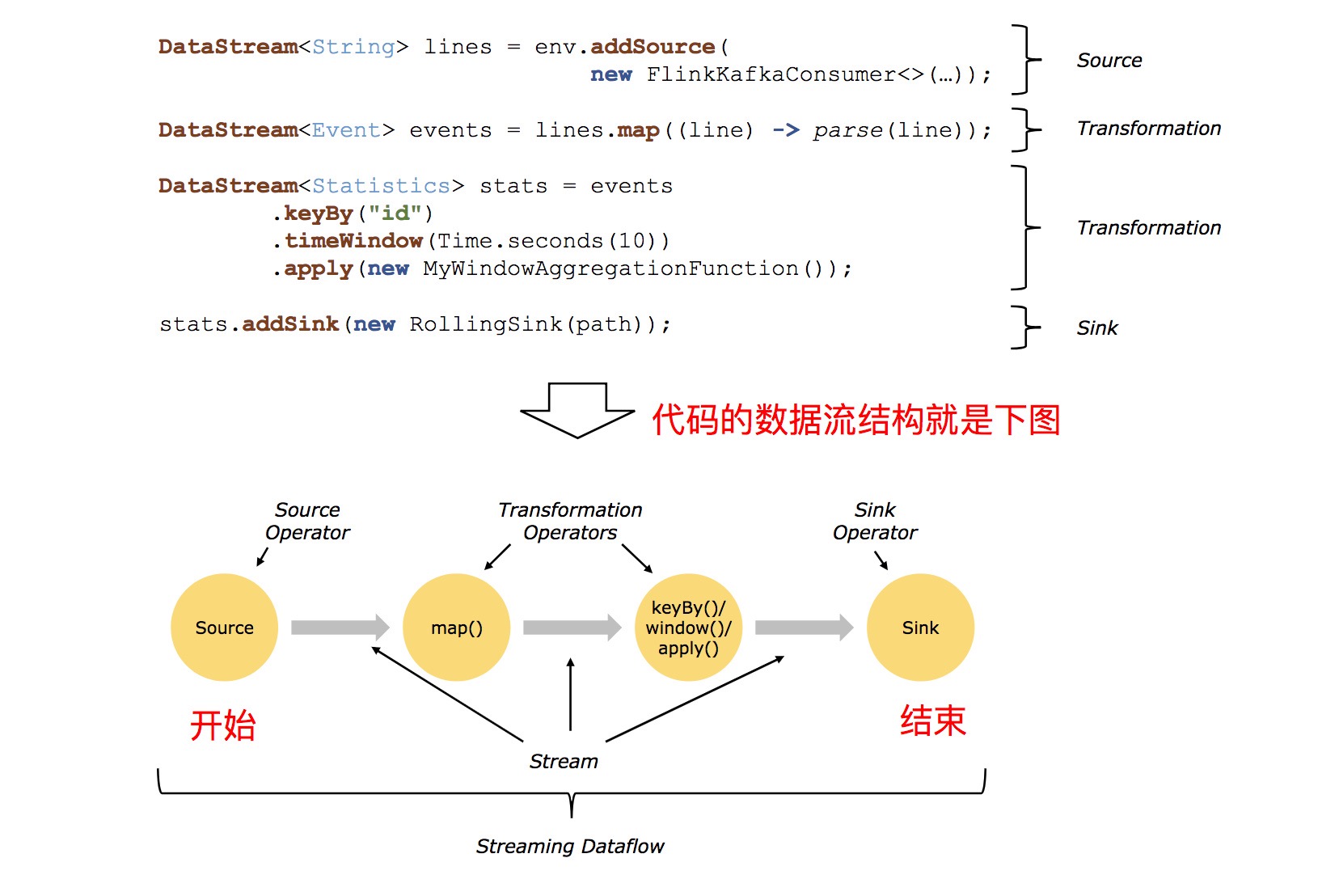
- Source: 数据源,Flink 在流处理和批处理上的 source 大概有 4 类:基于本地集合的 source、基于文件的 source、基于网络套接字的 source、自定义的 source。自定义的 source 常见的有 Apache kafka、Amazon Kinesis Streams、RabbitMQ、Twitter Streaming API、Apache NiFi 等,当然你也可以定义自己的 source。