API
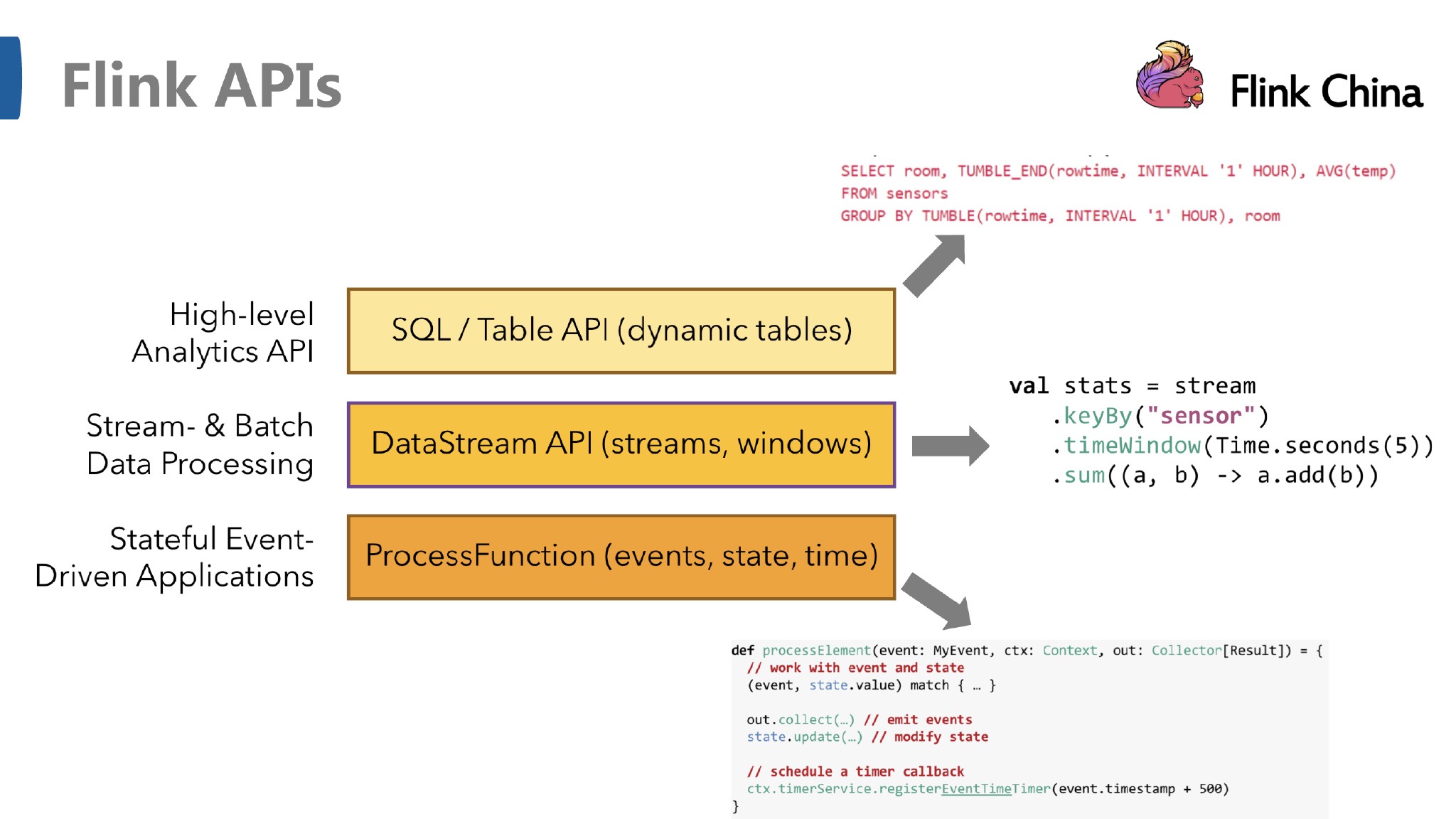
DataStream API是基于数据流的也就是所谓的无界数据,它可以对数据流进行转换、过滤、聚合等操作,并且支持事件时间和处理时间窗口。DataStream API还提供了状态管理机制来存储和更新中间结果。
DataSet API则是用来处理有界数据集的。它类似于Hadoop的MapReduce,支持批量处理数据。DataSet API提供了各种转换操作,如map、filter、reduce、join等,以及自定义函数和用户定义的聚合函数。
Table API 是以 表 为中心的声明式 DSL,其中表可能会动态变化(在表达流数据时)。Table API 提供了例如 select、project、join、group-by、aggregate 等操作,使用起来却更加简洁(代码量更少)。
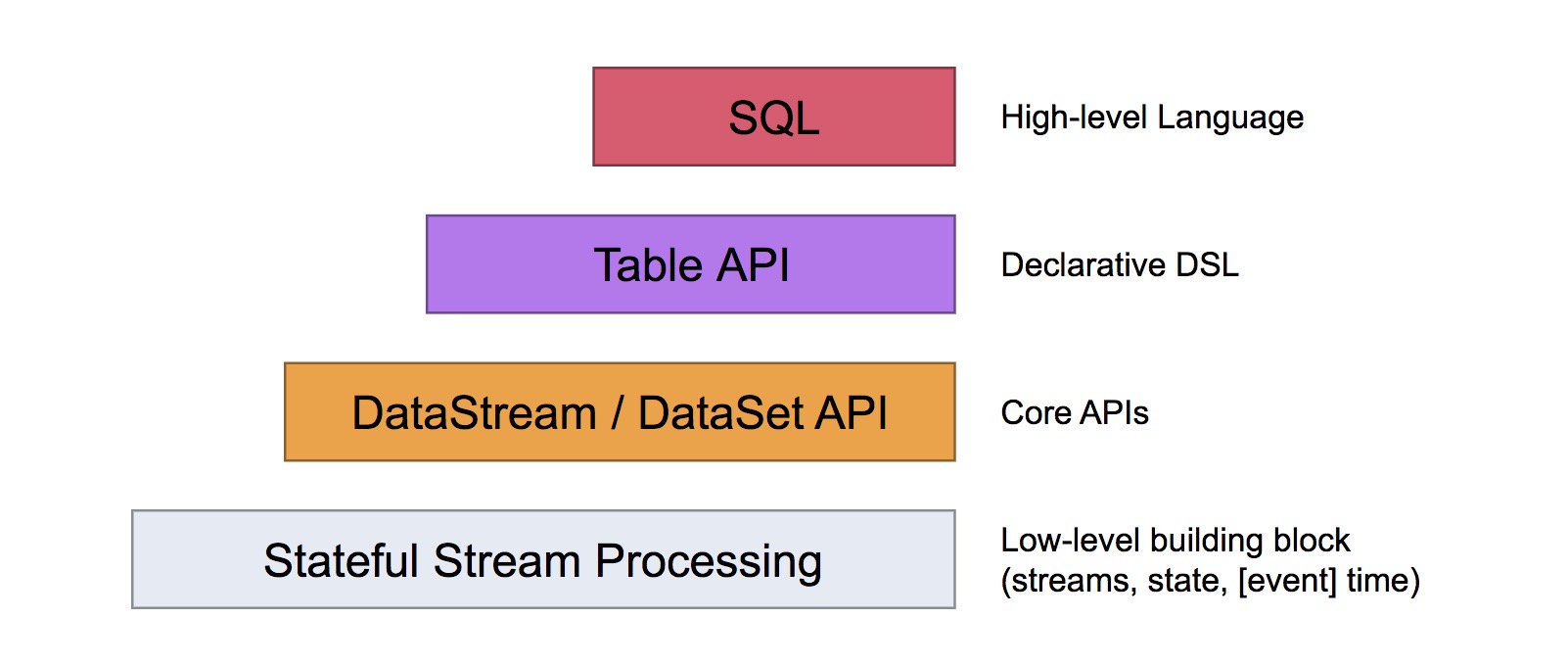
本文主要介绍DataStream API。
DataStream API
DataStream API 得名于特殊的 DataStream 类,该类用于表示 Flink 程序中的数据集合。你可以认为 它们是可以包含重复项的不可变数据集合。这些数据可以是有界(有限)的,也可以是无界(无限)的,但用于处理它们的API是相同的。
DataStream 在用法上类似于常规的 Java 集合,但在某些关键方面却大不相同。它们是不可变的,这意味着一旦它们被创建,你就不能添加或删除元素。你也不能简单地察看内部元素,而只能使用 DataStream API 操作来处理它们,DataStream API 操作也叫作转换(transformation)。
你可以通过在 Flink 程序中添加 source 创建一个初始的 DataStream。然后,你可以基于 DataStream 派生新的流,并使用 map、filter 等 API 方法把 DataStream 和派生的流连接在一起。
基本处理流程:
DataStream:表示一个无限的数据流。可以从外部数据源读取(例如从kafka读取,生成一个kafkaStream),也可以通过DataStream API链式组合生成。
Transformation:DataStream API提供了许多转换操作,如map、filter、reduce、keyBy、window等。这些操作可以按顺序进行链式组合,构成一个完整的数据处理流程。
Window:在无限数据流中,我们通常需要对数据进行分组并在一段时间内进行聚合计算。Window操作就是将数据流按照指定的Key值进行分组,并且按照指定的时间窗口进行切分,然后在每个窗口中对数据进行聚合计算。
Time:Flink支持两种时间模型:EventTime和ProcessingTime。EventTime是指事件发生的真实时间,而ProcessingTime是指处理事件的机器时间。在DataStream API中,可以使用timestampAssigner和watermark来处理EventTime模型。
State:由于数据流是无限的,因此在处理数据时需要保存中间结果。Flink提供了状态管理机制来存储和更新中间结果。在DataStream API中,可以使用ValueState、ListState、MapState、ReductionState等类型的状态。
Sink:最后,可以将处理后的数据流输出到指定的Sink中,如Kafka、HDFS、MySQL等。
e.g. 下面代码是一个从kafka读取一个简单的用户登录信息数据数据,然后对用户登录次数进行count的例子。
1 | package com.zzx.springboottest.demo; |

