为什么要使用主从复制?
从数据库(Slave)是主数据库的备份,当主数据库(Master)变化时从数据库要更新,这些数据库软件可以设计更新周期。这是提高信息安全的手段。主从数据库服务器不在一个地理位置上,当发生意外时数据库可以保存。
其中Master负责写操作的负载,也就是说一切写的操作都在Master上进行,而读的操作则分摊到Slave上进行。这样一来的可以大大提高读取的效率。在一般的互联网应用中,经过一些数据调查得出结论,读/写的比例大概在 10:1左右 ,也就是说大量的数据操作是集中在读的操作,这也就是为什么我们会有多个Slave的原因。但是为什么要分离读和写呢?熟悉DB的研发人员都知道,写操作涉及到锁的问题,不管是行锁还是表锁还是块锁,都是比较降低系统执行效率的事情。我们这样的分离是把写操作集中在一个节点上,而读操作其其他的N个节点上进行,从另一个方面有效的提高了读的效率,保证了系统的高可用性。
主从复制基本过程
- Mysql的主从同步就是当master(主库)发生数据变化的时候,会实时同步到slave(从库)。
- 主从复制可以水平扩展数据库的负载能力,容错,高可用,数据备份。
- 不管是delete、update、insert,还是创建函数、存储过程,都是在master上,当master有操作的时候,slave会快速的接受到这些操作,从而做同步。
因此slave(从库)在设置是在my.cnf中设置readonly 尽量避免在从库写入。从库只负责读取。
主从同步的粒度、原理和形式
三种主要实现粒度(statement、row、mixed)
- statement: 会将对数据库操作的sql语句写道binlog中
- row: 会将每一条数据的变化写道binlog中。
- mixed: statement与row的混合。Mysql决定何时写statement格式的binlog, 何时写row格式的binlog。
一般使用row即可
主要的实现原理、具体操作、示意图
- 在master机器上的操作:
当master上的数据发生变化时,该事件变化会按照顺序写入bin-log中。当slave链接到master的时候,master机器会为slave开启binlog dump线程。当master的binlog发生变化的时候,bin-log dump线程会通知slave,并将相应的binlog内容发送给slave。 - 在slave机器上操作:
当主从同步开启的时候,slave上会创建两个线程:I\O线程。该线程连接到master机器,master机器上的binlog dump 线程会将binlog的内容发送给该I\O线程。该I/O线程接收到binlog内容后,再将内容写入到本地的relay log;sql线程。该线程读取到I/O线程写入的ralay log。并且根据relay log。并且根据relay log 的内容对slave数据库做相应的操作。
原理图如下: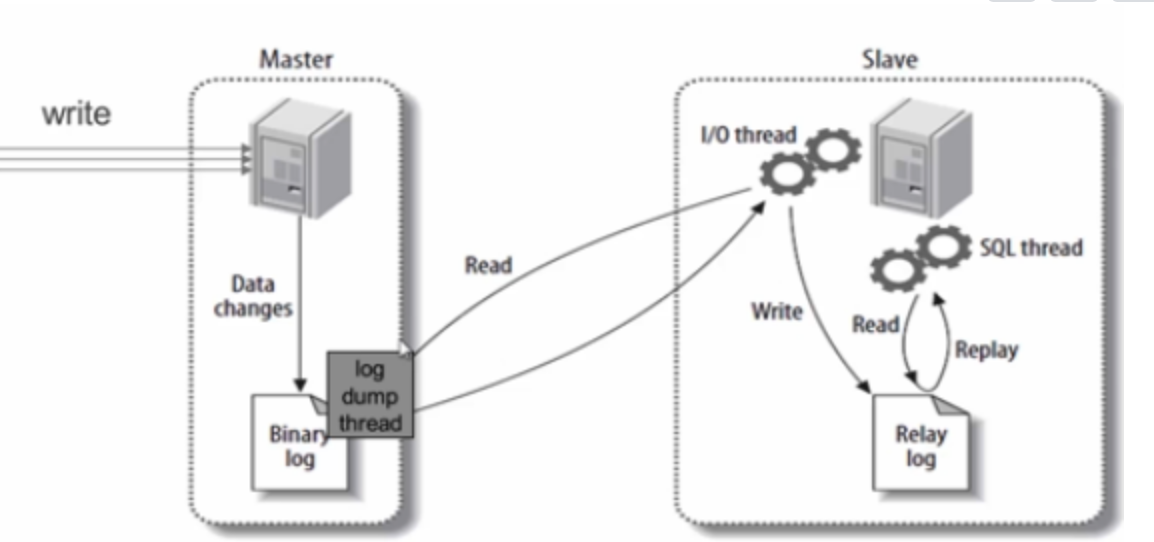
- 从库生成两个线程,一个I/O线程,一个SQL线程;
- i/o线程去请求主库 的binlog,并将得到的binlog日志写到relay log(中继日志) 文件中;
- 主库会生成一个 log dump 线程,用来给从库 i/o线程传binlog;
- SQL 线程,会读取relay log文件中的日志,并解析成具体操作,来实现主从的操作一致,而最终数据一致;
主从同步的延迟等问题、原因及解决方案
相关参数:1
2
3
4
5
6
7
8
9mysql> SHOW SLAVE STATUS\G
Master_Log_File: SLAVE中的I/O线程当前正在读取的主服务器二进制日志文件的名称
Read_Master_Log_Pos: 在当前的主服务器二进制日志中,SLAVE中的I/O线程已经读取的位置
Relay_Log_File: SQL线程当前正在读取和执行的中继日志文件的名称
Relay_Log_Pos: 在当前的中继日志中,SQL线程已读取和执行的位置
Relay_Master_Log_File: 由SQL线程执行的包含多数近期事件的主服务器二进制日志文件的名称
Slave_IO_Running: I/O线程是否被启动并成功地连接到主服务器上
Slave_SQL_Running: SQL线程是否被启动
Seconds_Behind_Master: 从属服务器SQL线程和从属服务器I/O线程之间的时间差距,单位以秒计。
从库同步延迟可能会出现如下状况:
- show slave status显示参数Seconds_Behind_Master不为0,这个数值可能会很大
- show slave status显示参数Relay_Master_Log_File和Master_Log_File显示bin-log的编号相差很大,说明bin-log在从库上没有及时同步,所以近期执行的bin-log和当前IO线程所读的bin-log相差很大
- mysql的从库数据目录下存在大量mysql-relay-log日志,该日志同步完成之后就会被系统自动删除,存在大量日志,说明主从同步延迟很厉害
从库同步的延迟问题
MySQL数据库主从同步延迟原理mysql主从同步原理:
主库针对写操作,顺序写binlog,从库单线程去主库顺序读”写操作的binlog”,从库取到binlog在本地原样执行(随机写),来保证主从数据逻辑上一致。mysql的主从复制都是单线程的操作,主库对所有DDL和DML产生binlog,binlog是顺序写,所以效率很高,slave的Slave_IO_Running线程到主库取日志,效率比较高,下一步,问题来了,slave的Slave_SQL_Running线程将主库的DDL和DML操作在slave实施。DML和DDL的IO操作是随即的,不是顺序的,成本高很多,还可能可slave上的其他查询产生lock争用,由于Slave_SQL_Running也是单线程的,所以一个DDL卡主了,需要执行10分钟,那么所有之后的DDL会等待这个DDL执行完才会继续执行,这就导致了延时。有朋友会问:“主库上那个相同的DDL也需要执行10分,为什么slave会延时?”,答案是master可以并发,Slave_SQL_Running线程却不可以。MySQL数据库主从同步延迟是怎么产生的?
当主库的TPS并发较高时,产生的DDL数量超过slave一个sql线程所能承受的范围,那么延时就产生了,当然还有就是可能与slave的大型query语句产生了锁等待。首要原因:数据库在业务上读写压力太大,CPU计算负荷大,网卡负荷大,硬盘随机IO太高次要原因:读写binlog带来的性能影响,网络传输延迟。
MySql数据库从库同步的延迟解决方案
- 架构方面
- 业务的持久化层的实现采用分库架构,mysql服务可平行扩展,分散压力。
- 单个库读写分离,一主多从,主写从读,分散压力。这样从库压力比主库高,保护主库。
- 服务的基础架构在业务和mysql之间加入memcache或者redis的cache层。降低mysql的读压力。
- 不同业务的mysql物理上放在不同机器,分散压力。
- 使用比主库更好的硬件设备作为slave总结,mysql压力小,延迟自然会变小。
- 硬件方面
- 采用好服务器,比如4u比2u性能明显好,2u比1u性能明显好。
- 存储用ssd或者盘阵或者san,提升随机写的性能。
- 主从间保证处在同一个交换机下面,并且是万兆环境。
总结,硬件强劲,延迟自然会变小。一句话,缩小延迟的解决方案就是花钱和花时间。
- mysql主从同步加速
- sync_binlog在slave端设置为0
–logs-slave-updates从服务器从主服务器接收到的更新不记入它的二进制日志。- 直接禁用slave端的binlog
- slave端,如果使用的存储引擎是innodb,
innodb_flush_log_at_trx_commit =2
- master端修改linux、Unix文件系统中文件的etime属性, 由于每当读文件时OS都会将读取操作发生的时间回写到磁盘上,对于读操作频繁的数据库文件来说这是没必要的,只会增加磁盘系统的负担影响I/O性能。可以通过设置文件系统的mount属性,组织操作系统写atime信息,在linux上的操作为:打开/etc/fstab,加上noatime参数/dev/sdb1 /data reiserfs noatime 1 2然后重新mount文件系统#mount -oremount /data
- 同步参数调整主库是写,对数据安全性较高,比如
sync_binlog=1,innodb_flush_log_at_trx_commit = 1之类的设置是需要的而slave则不需要这么高的数据安全,完全可以讲sync_binlog设置为0或者关闭binlog,innodb_flushlog也可以设置为0来提高sql的执行效率
sync_binlog=1MySQL提供一个sync_binlog参数来控制数据库的binlog刷到磁盘上去。默认,sync_binlog=0,表示MySQL不控制binlog的刷新,由文件系统自己控制它的缓存的刷新。这时候的性能是最好的,但是风险也是最大的。一旦系统Crash,在binlog_cache中的所有binlog信息都会被丢失。如果
sync_binlog>0,表示每sync_binlog次事务提交,MySQL调用文件系统的刷新操作将缓存刷下去。最安全的就是sync_binlog=1了,表示每次事务提交,MySQL都会把binlog刷下去,是最安全但是性能损耗最大的设置。这样的话,在数据库所在的主机操作系统损坏或者突然掉电的情况下,系统才有可能丢失1个事务的数据。但是binlog虽然是顺序IO,但是设置sync_binlog=1,多个事务同时提交,同样很大的影响MySQL和IO性能。虽然可以通过group commit的补丁缓解,但是刷新的频率过高对IO的影响也非常大。对于高并发事务的系统来说,“sync_binlog”设置为0和设置为1的系统写入性能差距可能高达5倍甚至更多。所以很多MySQL DBA设置的sync_binlog并不是最安全的1,而是2或者是0。这样牺牲一定的一致性,可以获得更高的并发和性能。默认情况下,并不是每次写入时都将binlog与硬盘同步。因此如果操作系统或机器(不仅仅是MySQL服务器)崩溃,有可能binlog中最后的语句丢失了。要想防止这种情况,你可以使用sync_binlog全局变量(1是最安全的值,但也是最慢的),使binlog在每N次binlog写入后与硬盘同步。即使sync_binlog设置为1,出现崩溃时,也有可能表内容和binlog内容之间存在不一致性。
innodb_flush_log_at_trx_commit(这个很管用)抱怨Innodb比MyISAM慢 100倍?那么你大概是忘了调整这个值。默认值1的意思是每一次事务提交或事务外的指令都需要把日志写入(flush)硬盘,这是很费时的。特别是使用电池供电缓存(Battery backed up cache)时。设成2对于很多运用,特别是从MyISAM表转过来的是可以的,它的意思是不写入硬盘而是写入系统缓存。日志仍然会每秒flush到硬 盘,所以你一般不会丢失超过1-2秒的更新。设成0会更快一点,但安全方面比较差,即使MySQL挂了也可能会丢失事务的数据。而值2只会在整个操作系统 挂了时才可能丢数据。ls命令可用来列出文件的 atime、ctime 和 mtime。
atime 文件的access time 在读取文件或者执行文件时更改的ctime 文件的create time 在写入文件,更改所有者,权限或链接设置时随inode的内容更改而更改mtime 文件的modified time 在写入文件时随文件内容的更改而更改ls -lc filename 列出文件的 ctimels -lu filename 列出文件的 atimels -l filename 列出文件的 mtimestat filename 列出atime,mtime,ctimeatime不一定在访问文件之后被修改因为:使用ext3文件系统的时候,如果在mount的时候使用了noatime参数那么就不会更新atime信息。这三个time stamp都放在 inode 中.如果mtime,atime 修改,inode 就一定会改, 既然 inode 改了,那ctime也就跟着改了.之所以在 mount option 中使用 noatime, 就是不想file system 做太多的修改, 而改善读取效能
Mysql主从同步延时应用端解决方案
- 二次读取
二次读取的意思就是读从库没读到之后再去主库读一下,只要通过对数据库访问的API进行封装就能实现这个功能。很简单,并且和业务之间没有耦合。但是有个问题,如果有很多二次读取相当于压力还是回到了主库身上,等于读写分离白分了。而且如有人恶意攻击,就一直访问没有的数据,那主库就可能爆了。 - 写之后的马上的读操作访问主库
也就是写操作之后,立马的读操作指定访问主库,之后的读操作采取访问从库。这就等于写死了,和业务强耦合了。 - 关键业务读写都由主库承担,非关键业务读写分离
类似付钱的这种业务,读写都到主库,避免延迟的问题,但是例如改个头像啊,个人签名这种比较不重要的就读写分离,查询都去从库查,毕竟延迟一下影响也不大。 - 事务一致性问题
同一线程且同一数据路连接内,如果有写入操作,则以后的读操作都从主库读取,以保持数据一致性。(与2有共通之处,具体情况具体分析)
如何实现应用端的延时处理
一般有两种方式:代码封装、数据库中间件。
代码封装
代码封装的实现很简单,就是抽出一个中间层,让这个中间层来实现读写分离和数据库连接。讲白点就是搞个provider封装了save,select等通常数据库操作,内部save操作的dataSource是主库的,select操作的dataSource是从库的。
优点: 就是实现简单,并且可以根据业务定制化变化,随心所欲。
缺点:就是是如果哪个数据库宕机了,发生主从切换了之后,就得修改配置重启。并且如果你的系统很大,一个业务可能包含多个子系统,一个子系统是java写的一个子系统用go写的,这样的话得分别为不同语言实现一套中间层,重复开发。数据库中间件
就是有一个独立的系统,专门来实现读写分离和数据库连接管理,业务服务器和数据库中间件之间是通过标准的SQL协议交流的,所以在业务服务器看来数据库中间件其实就是个数据库。
优点:因为是通过sql协议的所以可以兼容不同的语言不需要单独写一套,并且有中间件来实现主从切换,业务服务器不需要关心这点。
缺点:多了一个系统其实就等于多了一个关心。。如果数据库中间件挂了的话对吧,而且多了一个系统就等于多了一个瓶颈,所以对中间件的性能要求也高,并且所有的数据库操作都要经过它。并且中间件实现很复杂,难度比代码封装高多了。

