to young people
1 | You cannot improve your past, but you can improve your future. Once time is wasted, life is wasted. |
家里的AIO服务器硬盘原本是2T+4T组合,2T硬盘上部署了emby等服务,4T硬盘上存放了大量的视频文件。由于2T硬盘空间不足,所以需要将2T硬盘替换为4T硬盘,然后将原来4T硬盘位换一个大容量的硬盘。
网上选购了一段时间,考虑到性价比等因素最后网购了一个12T的希捷银河企业盘,体验一下炒豆子的感觉。
迁移要先把4T硬盘的数据直接拷贝到12T硬盘上,然后格式化4T硬盘,再将2T硬盘的数据拷贝到4T硬盘上。最终将2T硬盘替换为4T硬盘。
迁移4T硬盘的数据到12T硬盘上没有遇到什么问题,因为原本4T就是数据盘,没有乱七八糟的分区,直接拷贝即可。
对比了多种全盘拷贝方法,最后使用了 dd 命令方法,dd 命令可以将整个硬盘的数据拷贝到另一个硬盘上,拷贝完成后,新硬盘的分区表和原硬盘一样,不需要再次分区,甚至UUID都一样,拷贝完成后直接挂载即可.
以下操作都是在硬盘未挂载的情况下进行的,AIO宿主机是PVE系统,最终硬盘是通过硬盘直通到ubuntu虚拟机上的。因此只需要将ubuntu虚拟机关机,登录pve终端操作即可。
线上运行的网络请求代理服务通过Grafana面板查看内存占用一直在上涨,给程序设置的内存上限为20G,已经占用8G,而且还在持续上涨,遂对程序进行排查。
通常直接使用jcmd直接查看堆内存占用情况,然后使用jmap工具导出堆内存快照,使用MAT工具分析堆内存快照,查看内存泄漏情况。
jcmd查看GC堆内存占用情况如下:1
2
3
4
5
6bash-4.4# jcmd 1 GC.heap_info
1:
garbage-first heap total 7536640K, used 6807512K [0x0000000300000000, 0x0000000800000000)
region size 16384K, 16 young (262144K), 1 survivors (16384K)
Metaspace used 116022K, committed 116736K, reserved 1155072K
class space used 13513K, committed 13952K, reserved 1048576K
在互联网中,我们的服务器一般都是联网的,所以服务器的时间同步一般都是通过ntp服务来实现的。但是在离线环境下,我们的服务器是无法联网的,
因为无法联网,所以无法使用ntp服务来同步时间。那么在离线环境下,我们如何实现多台服务器的时间同步呢?这里我们可以使用docker来实现。
核心思想就是在一台服务器上启动一个ntp服务,然后将这个ntp服务的时间同步到其他服务器上。
为什么使用docker服务来构建ntp服务器,因为docker服务可以在离线环境下安装,而且安装非常方便,只需要将docker镜像文件拷贝到离线环境下的服务器上。
还有一方面原因,如果安装例如离线的ntp服务,那么需要安装很多依赖包,安装依赖包就意味着会面领依赖性冲突等问题,导致安装过程比较繁琐。
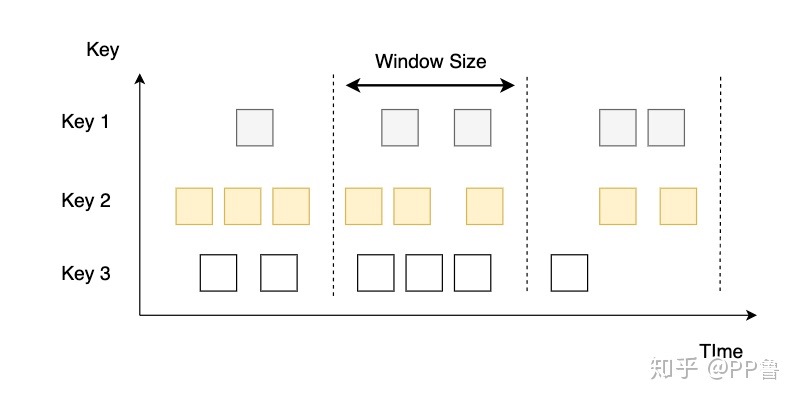
flink消费kafka流式数据时,使用数据的时间作为水印,当数据流中出现低频数据时,窗口不会关闭,导致数据一直在内存中。
实际场景:
假设当前时间为 2023-05-08 16:01:30,从kafka消费一条数据中的时间戳为2023:05:08 16:01:30,id为:A,并且以id为key,每5分钟统计一次。那么此时窗口的结束时间为2023-05-08 16:05:00,此时窗口不会关闭,因为在2023:05:08 16:05:00之前没有数据进来,要触发此窗口关闭必须消费一条超过2023-05-08 16:05:00并且id为A的数据。假如id为A的数据迟迟不来,则此窗口一直不会关闭,导致数据一直在内存中。
一个 Flink 程序由多个任务 task 组成(转换/算子、数据源和数据接收器)。一个 task 包括多个并行执行的实例,且每一个实例都处理 task 输入数据的一个子集。一个 task 的并行实例数被称为该 task 的 并行度 (parallelism)。
如果未显式设置,则默认的并行度为执行环境的默认并行度(通常是 CPU 的逻辑核心数)。
e.g. 在 Flink 里面代表每个算子的并行度,适当的提高并行度可以大大提高 Job 的执行效率,比如你的 Job 消费 Kafka 数据过慢,适当调大可能就消费正常了。
在 Flink 中,可以通过以下两种方式来设置数据流的并行度:
使用 setParallelism() 方法:这个方法适用于大多数算子(operator),包括 source、transform 和 sink。该方法接受一个整数参数,表示将数据流划分为多少个并行的任务(subtask)进行处理。例如,要将一个 source 的并行度设置为 4,可以使用以下代码:
1 | DataStreamSource<String> stream = env.addSource(new YourSourceFunction()); |
在执行环境(execution environment)中设置默认并行度:这个方法是全局性的,适用于所有算子。默认情况下,Flink 会自动根据执行环境的资源情况和负载均衡策略,自动地计算出算子的并行度。如果需要手动指定默认并行度,可以通过调用执行环境对象的 setParallelism() 方法来实现。例如,要将默认并行度设置为 8,可以使用以下代码:
1 | ExecutionEnvironment env = ExecutionEnvironment.getExecutionEnvironment(); |
值得注意的是,并不是所有算子都可以使用 setParallelism() 方法来设置并行度,比如在使用 KeyedStream 时,只能使用 keyBy() 方法来设置并行度。此外,并行度设置得太高或太低都可能会影响程序性能,需要根据具体场景进行优化。
flink 使用TumblingEventTimeWindows时,如果不设置Parallelism,则不会聚合计算
在 Flink 中使用 TumblingEventTimeWindows 时,如果未设置 Parallelism,则可能会出现以下两种情况之一:
如果输入数据流的并行度为 1,则无论是否设置 Parallelism,都会对整个数据流执行单个聚合操作,并生成单个结果。
如果输入数据流的并行度大于 1,则需要设置 Parallelism 才能确保正确的聚合计算。如果未设置 Parallelism,则会将窗口划分到多个任务中进行处理,每个任务只能看到其分配的子集数据,因此无法得到全局的聚合计算结果。
因此,为了确保正确的聚合计算,建议在使用 TumblingEventTimeWindows 时始终设置合适的 Parallelism。
Flink是一个容错的流处理框架,可以保证在节点故障、网络故障等异常情况下仍然能够保证数据处理和计算的正确性和完整性。Flink实现容错的主要方式是通过Checkpoint和重启机制。
Checkpoint:Checkpoint是一种机制,用于对作业状态进行周期性的快照。在Checkpoint过程中,Flink将当前作业的所有状态信息存储到持久化存储中,以便在发生故障时进行恢复。Flink支持多种Checkpoint协议,如exactly-once、at-least-once等,并且可以根据需要自定义Checkpoint间隔等参数。
重启机制:当发生故障并且无法通过Checkpoint恢复作业状态时,Flink会根据配置的重启策略进行重新启动。Flink提供了多种重启策略,如固定延迟重启、失败率重启等,并且可以设置最大尝试次数和时间间隔等参数。此外,Flink还支持增量式恢复,即只恢复部分状态而不是全部状态,从而提高恢复速度和效率。
通过Checkpoint和重启机制,Flink能够自动检测故障并进行恢复,从而使得数据处理系统更加健壮和可靠。同时,Flink还支持Exactly-Once语义,保证每条数据只会被处理一次,从而避免了重复计算和数据丢失的问题。
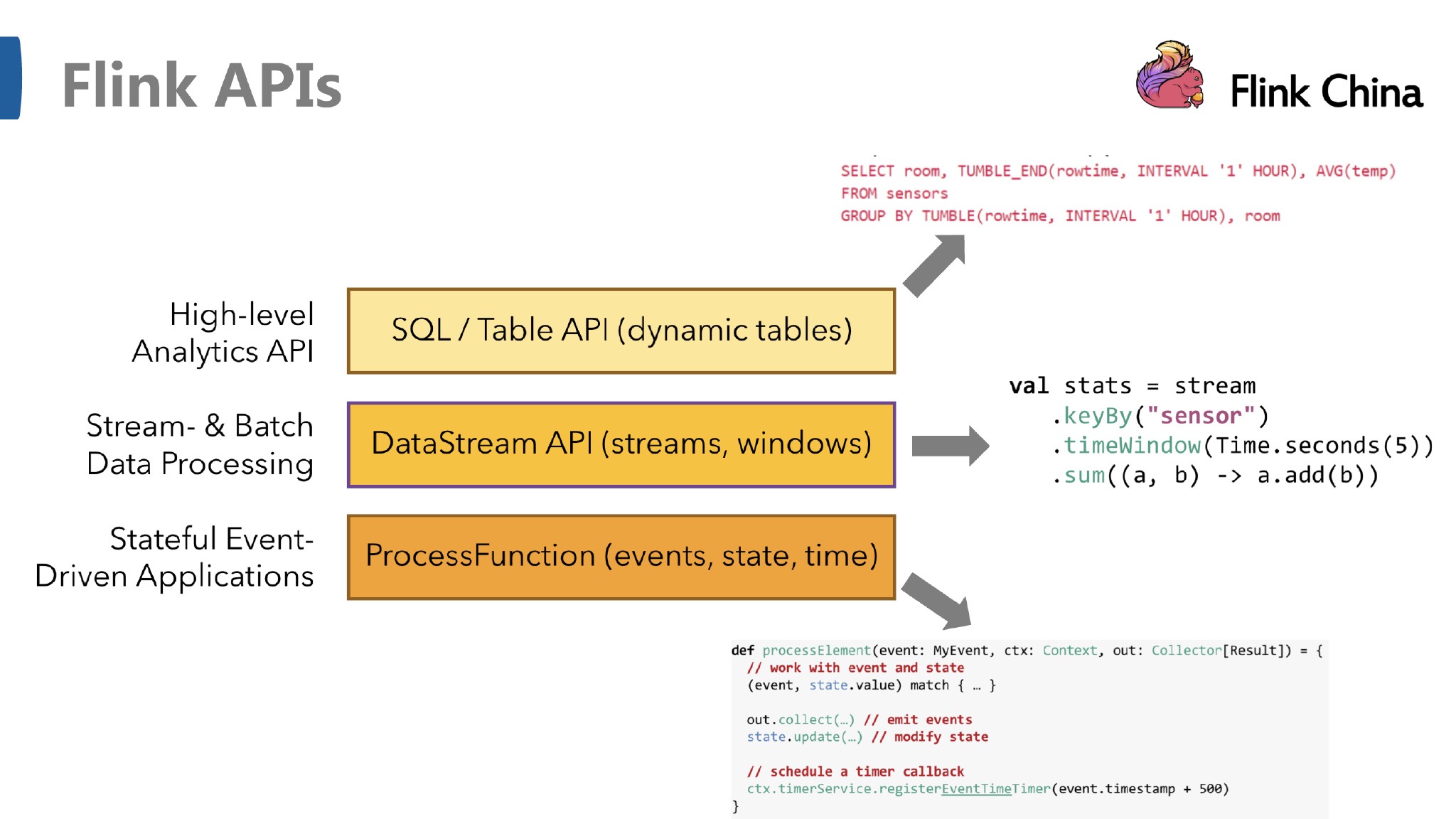
DataStream API是基于数据流的也就是所谓的无界数据,它可以对数据流进行转换、过滤、聚合等操作,并且支持事件时间和处理时间窗口。DataStream API还提供了状态管理机制来存储和更新中间结果。
DataSet API则是用来处理有界数据集的。它类似于Hadoop的MapReduce,支持批量处理数据。DataSet API提供了各种转换操作,如map、filter、reduce、join等,以及自定义函数和用户定义的聚合函数。
Table API 是以 表 为中心的声明式 DSL,其中表可能会动态变化(在表达流数据时)。Table API 提供了例如 select、project、join、group-by、aggregate 等操作,使用起来却更加简洁(代码量更少)。